2026
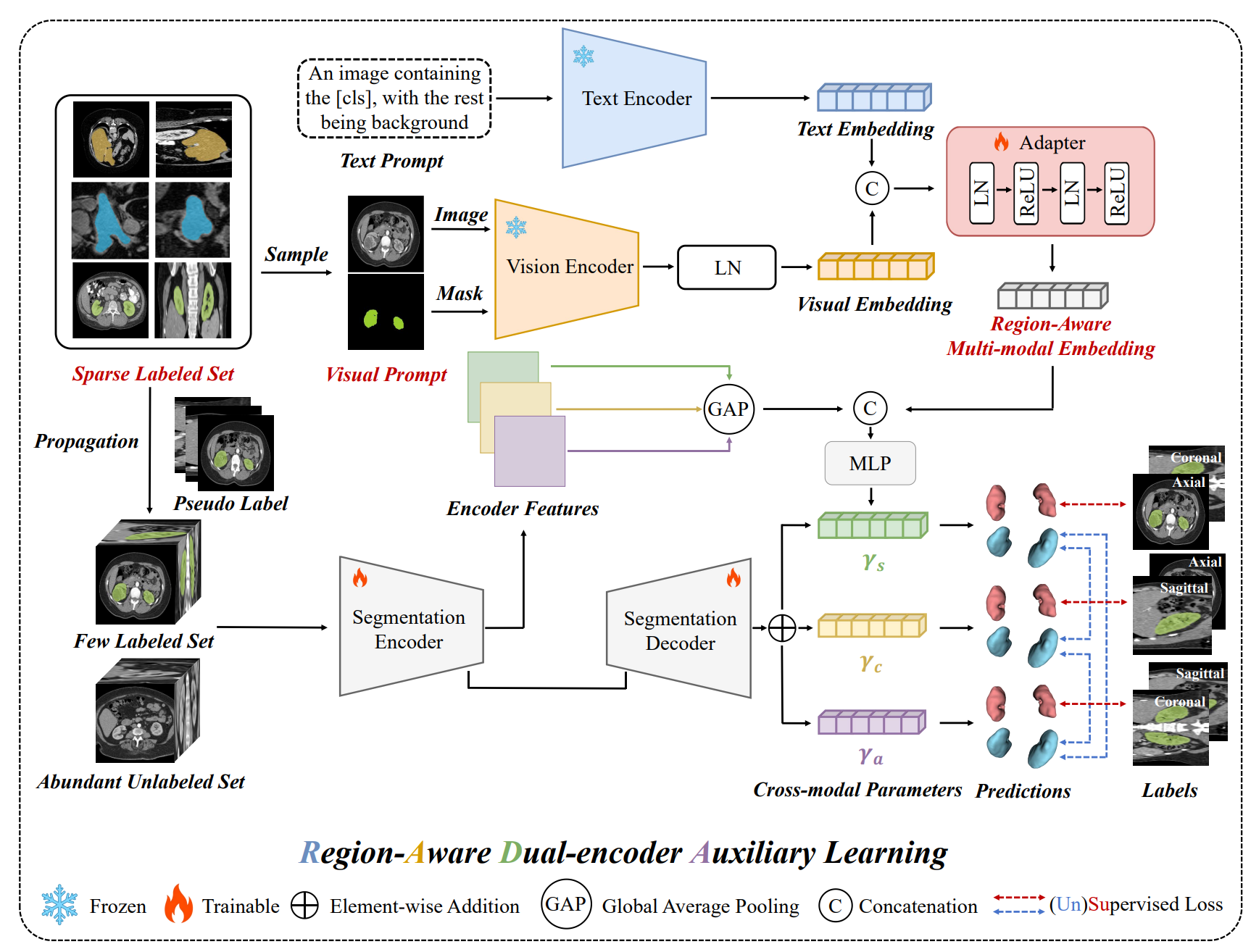
RADA: Region-Aware Dual-encoder Auxiliary Learning for Barely-supervised Medical Image Segmentation
Shuang Zeng, Boxu Xie, Lei Zhu, Xinliang Zhang, Jiakui Hu, Zhengjian Yao, Yuanwei Li, Yuxing Lu, Yanye Lu# (# corresponding author)
arxiv 2026
we propose RADA, a novel Region-Aware Dual-encoder Auxiliary learning pipeline which introduces a dual-encoder framework pre-trained on Alpha-CLIP to extract fine-grained, region-specific visual features from the original images and limited annotations for barely-supervised medical image segmentation.
RADA: Region-Aware Dual-encoder Auxiliary Learning for Barely-supervised Medical Image Segmentation
Shuang Zeng, Boxu Xie, Lei Zhu, Xinliang Zhang, Jiakui Hu, Zhengjian Yao, Yuanwei Li, Yuxing Lu, Yanye Lu# (# corresponding author)
arxiv 2026
we propose RADA, a novel Region-Aware Dual-encoder Auxiliary learning pipeline which introduces a dual-encoder framework pre-trained on Alpha-CLIP to extract fine-grained, region-specific visual features from the original images and limited annotations for barely-supervised medical image segmentation.
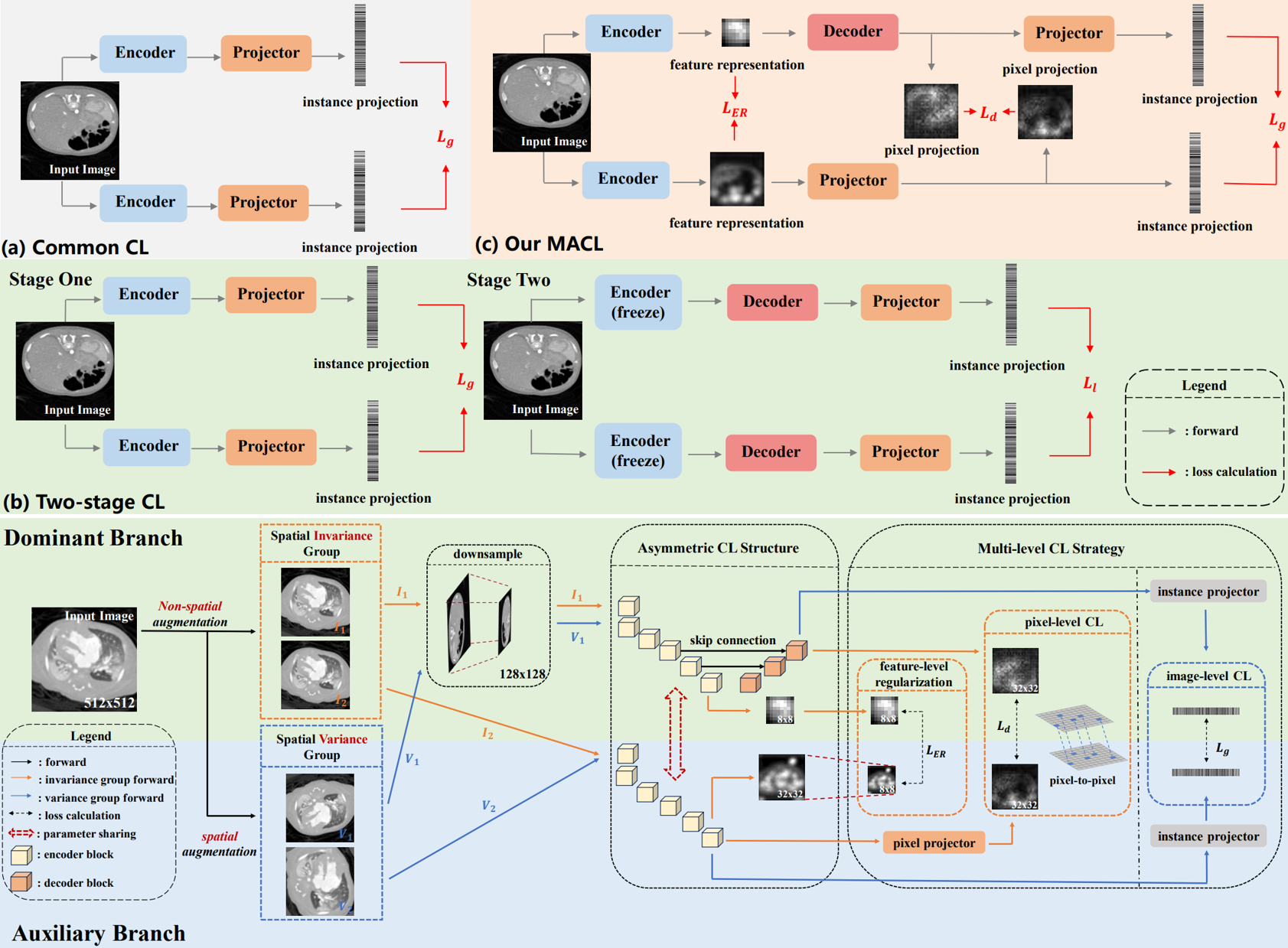
Multi-level Asymmetric Contrastive Learning for Medical Image Segmentation Pre-training
Shuang Zeng, Lei Zhu, Xinliang Zhang, Qian Chen, Hangzhou He, Lujia Jin, Zifeng Tian, Zhaoheng Xie, Micky C Nnamdi, Wenqi Shi, J Ben Tamo, May D. Wang, Yanye Lu# (# corresponding author)
IEEE Journal of Biomedical and Health Informatics 2026 中科院二区Top, IF:6.8
We propose a novel Multi-level Asymmetric Contrastive Learning framework named MACL by introducing an asymmetric CL structure and a multi-level CL strategy to realize one-stage encoder-decoder synchronous pre-training for medical image segmentation.
Multi-level Asymmetric Contrastive Learning for Medical Image Segmentation Pre-training
Shuang Zeng, Lei Zhu, Xinliang Zhang, Qian Chen, Hangzhou He, Lujia Jin, Zifeng Tian, Zhaoheng Xie, Micky C Nnamdi, Wenqi Shi, J Ben Tamo, May D. Wang, Yanye Lu# (# corresponding author)
IEEE Journal of Biomedical and Health Informatics 2026 中科院二区Top, IF:6.8
We propose a novel Multi-level Asymmetric Contrastive Learning framework named MACL by introducing an asymmetric CL structure and a multi-level CL strategy to realize one-stage encoder-decoder synchronous pre-training for medical image segmentation.
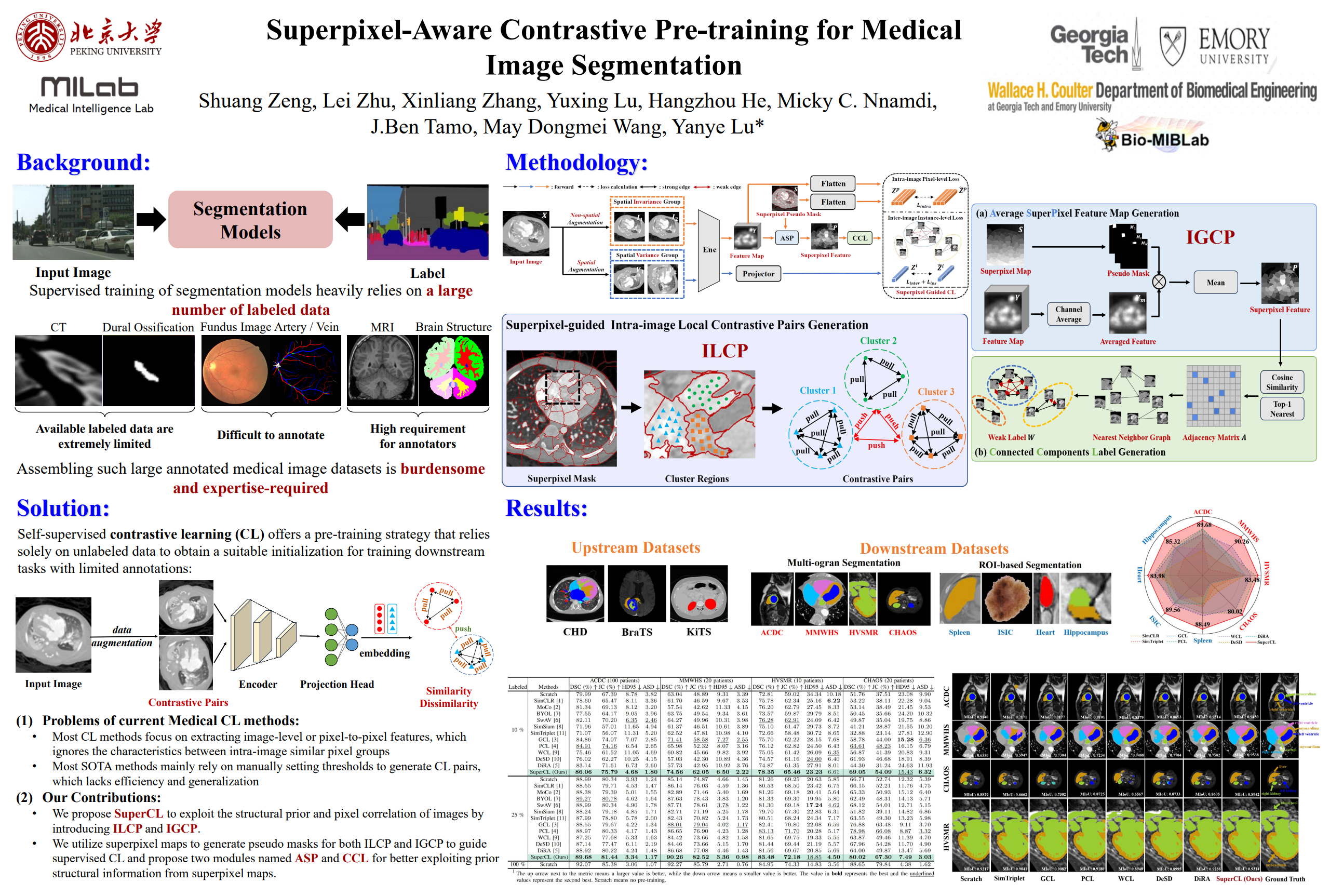
SuperCL: Superpixel Guided Contrastive Learning for Medical Image Segmentation Pre-training
Shuang Zeng, Lei Zhu, Xinliang Zhang, Hangzhou He, Yanye Lu# (# corresponding author)
IEEE Transactions on Image Processing 2026 中科院一区Top, IF:13.7
We propose SuperCL, a superpixel-guided contrastive learning framework for medical image segmentation pre-training, which exploits the structural prior and pixel correlation of images by introducing two novel contrastive pairs generation strategies: Intra-image Local Contrastive Pairs (ILCP) Generation and Inter-image Global Contrastive Pairs (IGCP) Generation.
SuperCL: Superpixel Guided Contrastive Learning for Medical Image Segmentation Pre-training
Shuang Zeng, Lei Zhu, Xinliang Zhang, Hangzhou He, Yanye Lu# (# corresponding author)
IEEE Transactions on Image Processing 2026 中科院一区Top, IF:13.7
We propose SuperCL, a superpixel-guided contrastive learning framework for medical image segmentation pre-training, which exploits the structural prior and pixel correlation of images by introducing two novel contrastive pairs generation strategies: Intra-image Local Contrastive Pairs (ILCP) Generation and Inter-image Global Contrastive Pairs (IGCP) Generation.
2025
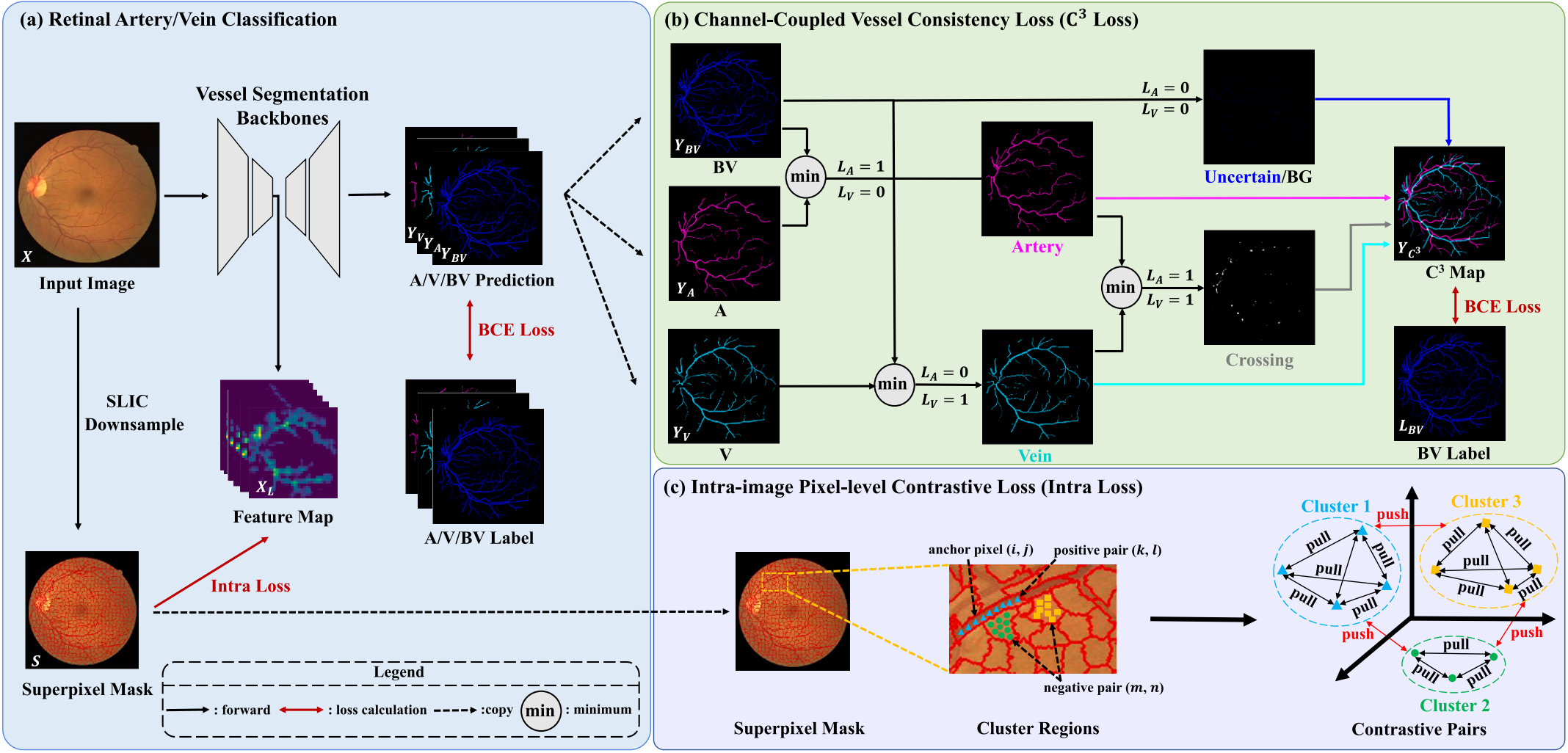
Improve retinal artery/vein classification via channel coupling
Shuang Zeng, Chee Hong Lee, Kaiwen Li, Boxu Xie, Ourui Fu, Hanghzou He, Lei Zhu#, Yanye Lu#, Fangxiao Cheng# (# corresponding author)
Expert Systems With Applications 2025 中科院一区Top, IF:7.5
We design a novel loss named Channel-Coupled Vessel Consistency Loss to enforce the coherence and consistency between vessel, artery and vein predictions and a regularization term named intra-image pixel-level contrastive loss to extract more discriminative feature-level fine-grained representations for accurate retinal A/V classification.
Improve retinal artery/vein classification via channel coupling
Shuang Zeng, Chee Hong Lee, Kaiwen Li, Boxu Xie, Ourui Fu, Hanghzou He, Lei Zhu#, Yanye Lu#, Fangxiao Cheng# (# corresponding author)
Expert Systems With Applications 2025 中科院一区Top, IF:7.5
We design a novel loss named Channel-Coupled Vessel Consistency Loss to enforce the coherence and consistency between vessel, artery and vein predictions and a regularization term named intra-image pixel-level contrastive loss to extract more discriminative feature-level fine-grained representations for accurate retinal A/V classification.
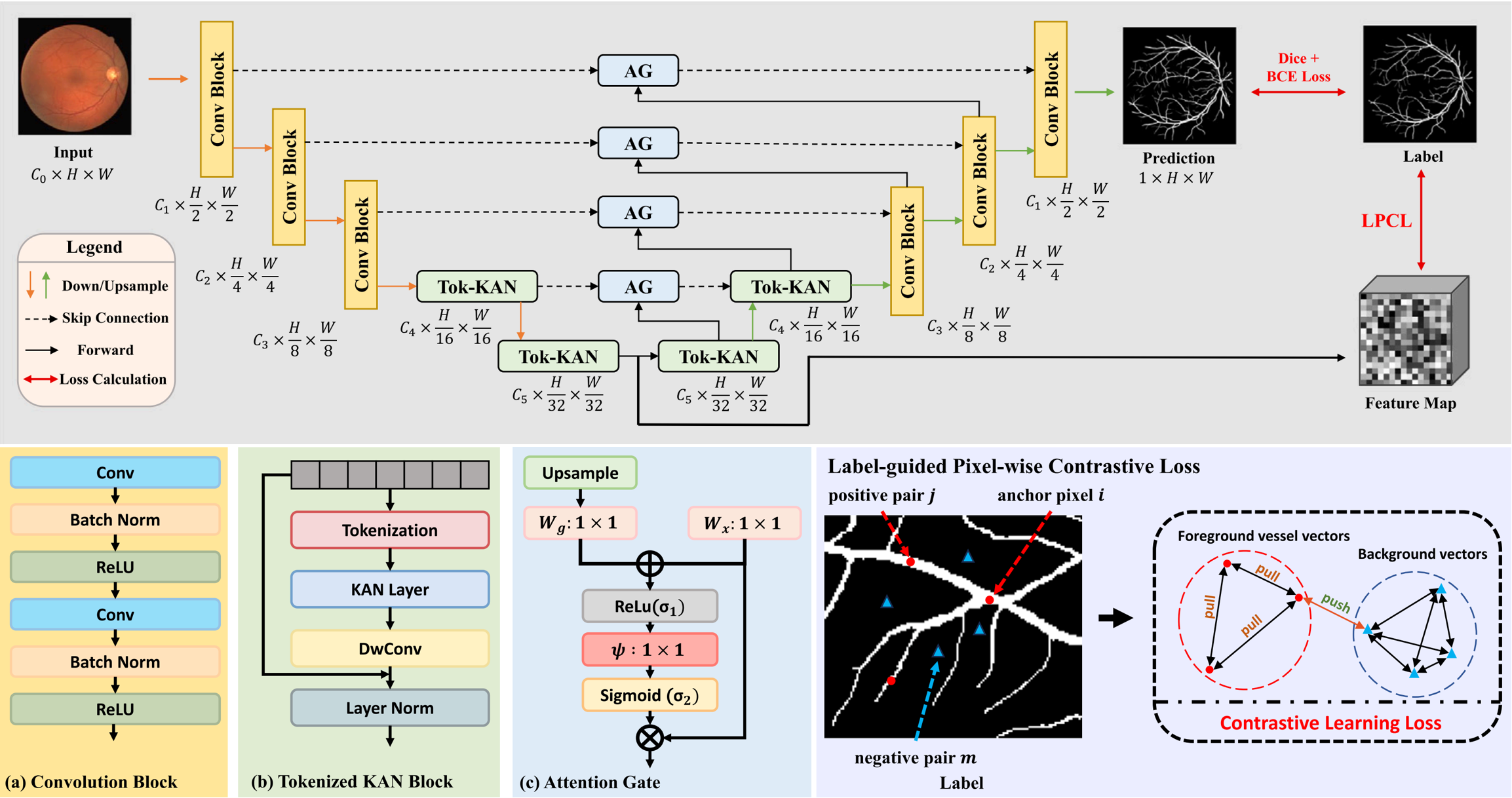
Novel extraction of discriminative fine-grained feature to improve retinal vessel segmentation
Shuang Zeng*, Chee Hong Lee*, Micky C. Nnamdi, Wenqi Shi, J. Ben Tamo, Hangzhou He, Xinliang Zhang, Qian Chen, May D. Wang, Lei Zhu#, Yanye Lu#, Qiushi Ren# (* equal contribution, # corresponding author)
Image and Vision Computing 2025
We propose a new retinal vessel segmentation model named AttUKAN to selectively filter skip connection features and a Label-guided Pixel-wise Contrastive Loss (LPCL) to extract more discriminative features by distinguishing between foreground vessel-pixel sample pairs and background sample pairs.
Novel extraction of discriminative fine-grained feature to improve retinal vessel segmentation
Shuang Zeng*, Chee Hong Lee*, Micky C. Nnamdi, Wenqi Shi, J. Ben Tamo, Hangzhou He, Xinliang Zhang, Qian Chen, May D. Wang, Lei Zhu#, Yanye Lu#, Qiushi Ren# (* equal contribution, # corresponding author)
Image and Vision Computing 2025
We propose a new retinal vessel segmentation model named AttUKAN to selectively filter skip connection features and a Label-guided Pixel-wise Contrastive Loss (LPCL) to extract more discriminative features by distinguishing between foreground vessel-pixel sample pairs and background sample pairs.
Publication Lists
- [21] 曾爽,卢闫晔 "一种基于多层级非对称对比学习的医学图像分割方法," 发明专利, 2025.
- [20] Zhengjian Yao, Jiakui Hu, Kaiwen Li, Hangzhou He, Xinliang Zhang, Shuang Zeng, et al. "Bridging Information Asymmetry: A Hierarchical Framework for Deterministic Blind Face Restoration," Transactions on Pattern Analysis and Machine Intelligence, 2026. [Paper]
- [19] Yuanwei Li, Xinliang Zhang, Hangzhou He, Kaiwen Li, Shuang Zeng, et al. "WeakMitoSAM: competitive prompt aggregation for point-supervised mitochondria segmentation in electron microscopy images," Biomedical Optics Express, 2026. [Paper]
- [18] Yuxing Lu, Xukai Zhao, J. Ben Tao, Micky C. Nnamdi, Rui Peng, Shuang Zeng, et al. "MetaBench: A Multi-task Benchmark for Assessing LLMs in Metabolomics," the Annual Meeting of the Association for Computational Linguistics (ACL), 2026. [Paper]
- [17] JiaKui Hu, Jialun Liu, Liying Yang, Xinliang Zhang, Kaiwen Li, Shuang Zeng, et al. "Geometry-as-context: Modulating Explicit 3D in Scene-consistent Video Generation to Geometry Context," IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2026. [Paper]
- [16] Shuang Zeng, et al. "Multi-level asymmetric contrastive learning for volumetric medical image segmentation pre-training," IEEE Journal of Biomedical and Health Informatics, 2026. [Paper]
- [15] Shuang Zeng, et al. "Supercl: Superpixel guided contrastive learning for medical image segmentation pre-training," IEEE Transactions on Image Processing, 2026. [Paper]
- [14] Shuang Zeng, et al. "Improve retinal artery/vein classification via channel coupling," Expert Systems With Applications, 2025. [Paper]
- [13] Shuang Zeng, et al. "Novel extraction of discriminative fine-grained feature to improve retinal vessel segmentation," Image and Vision Computing, 2025. [Paper]
- [12] Yuxing Lu, Goi Sin Yee, Shuang Zeng, et al. "MultiMed-RAG: Leveraging Multi-Source Knowledge and Agent Collaboration for Medical Tasks," IEEE Engineering in Medicine and Biology Society - Biomedical and Health Informatics (BHI), 2025. [Paper]
- [11] Yuxing Lu, Goi Sin Yee, Shuang Zeng, et al. "Assessing Large Language Models for Metabolomics," IEEE Engineering in Medicine and Biology Society - Biomedical and Health Informatics (BHI), 2025. [Paper]
- [10] Junmeng Li, Bei Rong, Lei Zhu, Ruilin Zhu, Xin Rong, Yuwei Wang, Yadi Zhang, Xiaopeng Gu, Shuang Zeng, et al. "One-Month Changes in Choroidal Vascularity Index of Medium Vessel Layer in Children with Myopia Wearing Orthokeratology Lenses: a Predictor for One-Year Changes in Axial Length," Ophthalmology and Therapy, 2025. [Paper]
- [9] Kaiwen Li, Hangzhou He, Shuang Zeng, et al. "Points-supervised Fundus Vessel Segmentation via Shape Priors and Contrastive Learning," IEEE Transactions on Medical Imaging (TMI), 2025. [Paper]
- [8] Hangzhou He, Lei Zhu, Xinliang Zhang, Shuang Zeng, et al. "V2C-CBM: Building Concept Bottlenecks with Vision-to-Concept Tokenizer," AAAI Conference on Artificial Intelligence (AAAI), 2025. [Paper]
- [7] Xinliang Zhang, Lei Zhu, Shuang Zeng, et al. "Exploiting Inherent Class Label: Towards Robust Scribble Supervised Semantic Segmentation," arXiv preprint, 2025. [Paper]
- [6] Lei Zhu, Xinliang Zhang, Hangzhou He, Qian Chen, Sha Li, Shuang Zeng, et al. "Branches Mutual Promotion for End-to-End Weakly Supervised Semantic Segmentation," IEEE Transactions on Neural Networks and Learning Systems (TNNLS), 2024. [Paper]
- [5] Yixin Chen, Xiangxi Meng, Yan Wang, Shuang Zeng, et al. "LUCIDA: Low-dose Universal-tissue CT Image Domain Adaptation For Medical Segmentation," Medical Image Computing and Computer Assisted Intervention (MICCAI), 2024. [Paper]
- [4] Qian Chen, Lei Zhu, Hangzhou He, Xinliang Zhang, Shuang Zeng, et al. "Low-Rank Mixture-of-Experts for Continual Medical Image Segmentation," Medical Image Computing and Computer Assisted Intervention (MICCAI), 2024. [Paper]
- [3] Lei Zhu, Junmeng Li, Yicheng Hu, Ruilin Zhu, Shuang Zeng, et al. "Choroidal Optical Coherence Tomography Angiography: Noninvasive Choroidal Vessel Analysis via Deep Learning," Health Data Science, 2024. [Paper]
- [2] Wenbo Zhang, Junmeng Li, Lei Zhu, Shuang Zeng, et al. "Choroidal Vascularity Index and Choroidal Structural Changes in Children With Nephrotic Syndrome," Translational Vision Science & Technology (TVST), 2024. [Paper]
- [1] Bin Qiu, Shuang Zeng, et al. "Comparative study of deep neural networks with unsupervised Noise2Noise strategy for noise reduction of optical coherence tomography images," Journal of Biophotonics, 2021. [Paper]